AI Development
AI-Driven Crawler for Market Data Acquisition
Our mission was to design a solution capable of collecting data from sources with both known and unknown structure, in order to build a comprehensive job listing database.
We aimed to verify the solution’s technical feasibility and cost-effectiveness, while continuously improving the quality of the output through iterative development.
What was the main challenge in this project?
The client had a single requirement — to obtain comprehensive market data at the desired level of quality. There was no predefined specification or standardized solution; the entire technical implementation was entrusted to our team.
A major challenge was the high level of uncertainty — it was impossible to predict whether the proposed solution would be technically viable or economically efficient. The process therefore required extensive experimentation, iteration, and continuous evaluation to optimize the solution and deliver the expected output quality.
What was your solution or approach?
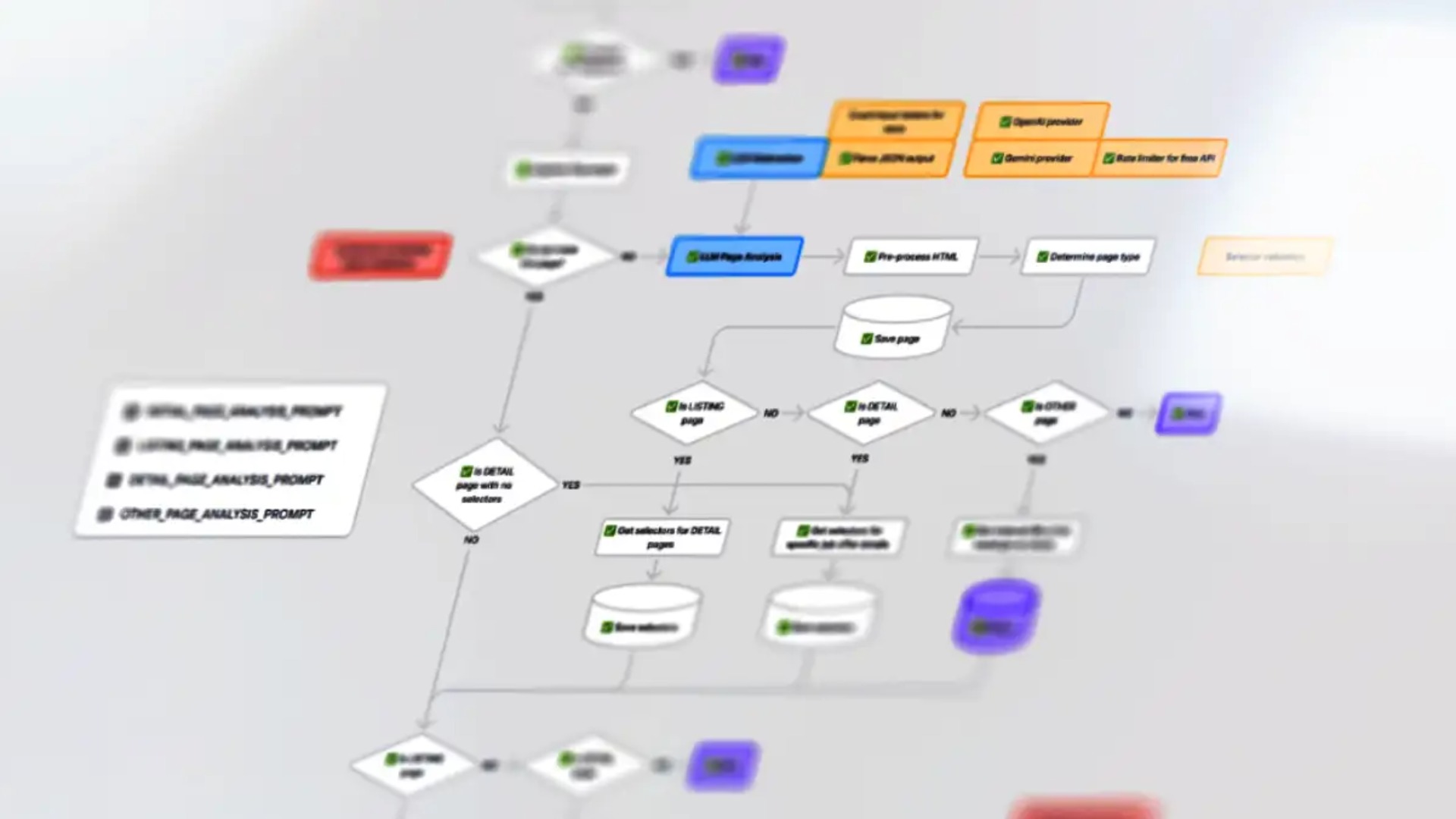
1. Initial Phase & Source Analysis
We began with an internal brainstorming process to explore possible solution paths. This was followed by the identification of relevant data sources across the Slovak web landscape. Each source was evaluated for technical accessibility and suitability for data extraction, with a focus on legal and ethical compliance.
2. Concept Testing (AI Branch)
Our initial testing focused on unstructured data sources. We developed a lightweight prototype to verify the technical feasibility of using AI for data extraction and evaluated early-stage outputs to assess quality and consistency.
3. Parallel Development of Both Branches
While refining the AI approach, we simultaneously implemented a more traditional extraction mechanism for sources with known structure. This parallel development ensured that both structured and unstructured data sources were addressed effectively, with the AI branch powered by a large language model (LLM).
4. Development, Testing & Optimization
To ensure long-term stability, we introduced request distribution mechanisms to avoid server overload or detection. The system was further enhanced with error handling, deduplication logic, and data-cleaning routines. We conducted both quantitative and qualitative validation of the output and continuously improved accuracy, relevance, and coverage through iterative cycles. The extraction logic was fine-tuned based on real-world feedback and evolving data formats.
5. Deployment & Ongoing Monitoring
After successful testing, the prototype was deployed and put into live operation. From there, we began continuous monitoring of its performance, allowing us to catch issues early and optimize the solution in real time.
What was the outcome or impact for the client?
Results & Business Impact:
Fully Functional Solution in Just 2 Months:
The Proof of Concept approach allowed us to validate both technical and economic viability quickly. Within just two months, we delivered a functional and tested prototype, ready for deployment and further scaling.
Iterative, Experimental Development Approach:
Rather than using a traditional linear development process, we adopted an agile and experimental approach that allowed us to respond flexibly to uncertainties and evolving requirements — ideal for fast-paced, innovation-driven domains like intelligent data extraction.
Risk Reduction and Hypothesis Validation:
The PoC format helped minimize initial investment risk while providing the client with concrete insights into how such a solution could perform in practice — before committing to full-scale product development.
Scalability and Reusability:
The solution was built to be transferable across countries, industries, and domains. It can be adapted to collect competitive intelligence, monitor market trends, product data, or any other relevant online information. Although new use cases may come with their own challenges, the core technology is highly reusable.
Other case studies from Cassovia Code

Software Development

E-commerce Development
Development of a Plugin for ONIX Integration for a UK Online Bookstore
APIREST APIwoocommerce

Mobile App Development

Web & Software Development
E-commerce Development
Other ai development case studies
AI Development
BBytecove
How We Built Convira: A Chatbot Development Services Case Study
next.jssupabaseshadcn+6

AI Development
AI Development
iindibus software
Case Studies Showcase – AI-Powered Bench Resource Management for Plug N Hire
AI Development
MMake My Brand
Accelerating Global Growth for MoogleLabs with Growth-as-a-Service
Branding AgencyDesign & DevelopmentUI/UX Design+6

AI Development
AI Development
KKodexo Labs
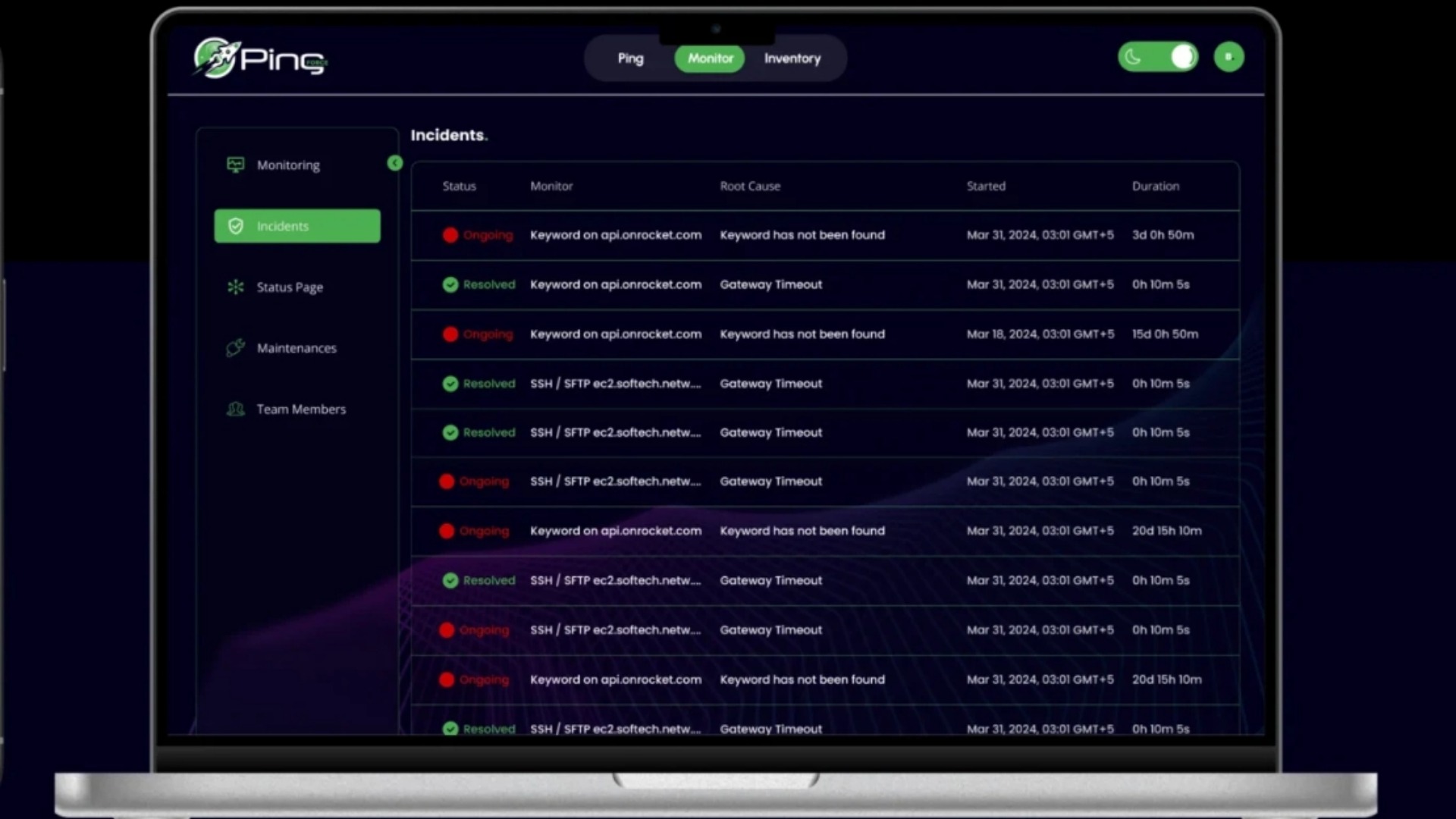
Ping Force – Web App for Seamless Networking & Communication
Software DevelopmentDesignQA and Testing+1
Project Details
Need similar services?
Agencies providing ai development
Posted this
C
We bridge technology and business, delivering end-to-end digital products, simplifying challenges, and empowering clients with exactly what they need and what they can skip.
T
Grow your business with us
M
Growth Partner for Strategic Innovation
T
Creating software for business needs and growth
O
OKVIPTOP - Cổng Game Quốc Tế Sở Hữu Nhiều Sân Chơi Uy Tín
S
B
Software That Actually Grows Your Business